AltcoinArchitect
AltcoinArchitect
Découvrir des protocoles gemmes avant qu'ils n'atteignent le top 100. Antécédents d'identification de projets 50x avant l'engouement. Analyses techniques et tokenomics approfondies sur l'infrastructure Web3 émergente.
- Récompense
- 6
- 5
- Partager
AllInDaddy :
:
C'est effectivement à la hauteur, fiable.Afficher plus
Des scientifiques chinois ont réalisé une percée dans le domaine des cellules solaires organiques, offrant de nouvelles idées pour la conception des matériaux des couches interfaciales et posant les bases de l'application commerciale à grande échelle des cellules solaires organiques.
SXP-1.7%

- Récompense
- 7
- 3
- Partager
DefiEngineerJack :
:
*sigh* Montrez-moi d'abord la mise en œuvre de la preuve de concept et les métriques d'efficacité.Afficher plus
- Récompense
- 9
- 4
- Partager
BugBountyHunter :
:
Cette opération est vraiment incroyable zkAfficher plus
La page d'état de la blockchain publique Base montre que le problème des arrêts de blocs anormaux dans le réseau Base a été résolu à 14:44 (UTC+8), et l'équipe officielle surveille continuellement la situation.
Voir l'original- Récompense
- 19
- 6
- Partager
GasFeeNightmare:
Enfin, ça bouge, hum.Afficher plus
🇺🇸 L'écart en IA se réduit, et la Chine arrive rapidement.
L'Amérique est toujours le poids lourd de l'IA, mais la Chine avance rapidement et réduit l'écart.
Les États-Unis avaient 40 top modèles l'année dernière, la Chine en avait 15. La différence de qualité ? Rétrécit rapidement.
L'Index IA de Stanford montre que les plateformes chinoises égalent désormais presque les homologues américains en termes de performance.
Voir l'originalL'Amérique est toujours le poids lourd de l'IA, mais la Chine avance rapidement et réduit l'écart.
Les États-Unis avaient 40 top modèles l'année dernière, la Chine en avait 15. La différence de qualité ? Rétrécit rapidement.
L'Index IA de Stanford montre que les plateformes chinoises égalent désormais presque les homologues américains en termes de performance.


- Récompense
- 7
- 4
- Partager
AirdropHunterKing :
:
L'IA américaine est devenue translucide, regardez qui prend les gens pour des idiots le plus.Afficher plus
Si un ordinateur quantique peut déchiffrer, il ne s'agit plus de déchiffrer cela, mais de déchiffrer le portefeuille de 1,1 million de Satoshi Nakamoto.
Voir l'original- Récompense
- 15
- 6
- Partager
FloorSweeper:
mdr, Satoshi ne va pas laisser ça arriver, vraiment.Afficher plus
- Récompense
- 12
- 4
- Partager
AirdropSkeptic :
:
Ah ? Les machines peuvent avoir une personnalité ?Afficher plus
Photo originale
Voir l'original
- Récompense
- 14
- 2
- Partager
PretendingToReadDocs:
Les détails sont dans le Livre blanc… Tu l'as vu ?Afficher plus
Nasdaq accélère des décisions d'investissement plus intelligentes avec une IA évolutive de niveau entreprise.
En adoptant des technologies d'IA avancées, Nasdaq a construit une plateforme d'IA qui offre :
⚡ 30% temps de réponse plus rapides
🎯 30% hausse de précision
📊 Informations en temps réel à grande échelle
En adoptant des technologies d'IA avancées, Nasdaq a construit une plateforme d'IA qui offre :
⚡ 30% temps de réponse plus rapides
🎯 30% hausse de précision
📊 Informations en temps réel à grande échelle
TIMES-13.47%

- Récompense
- 11
- 6
- Partager
LuckyBlindCat:
Avoir de l'argent, c'est être capricieux.Afficher plus
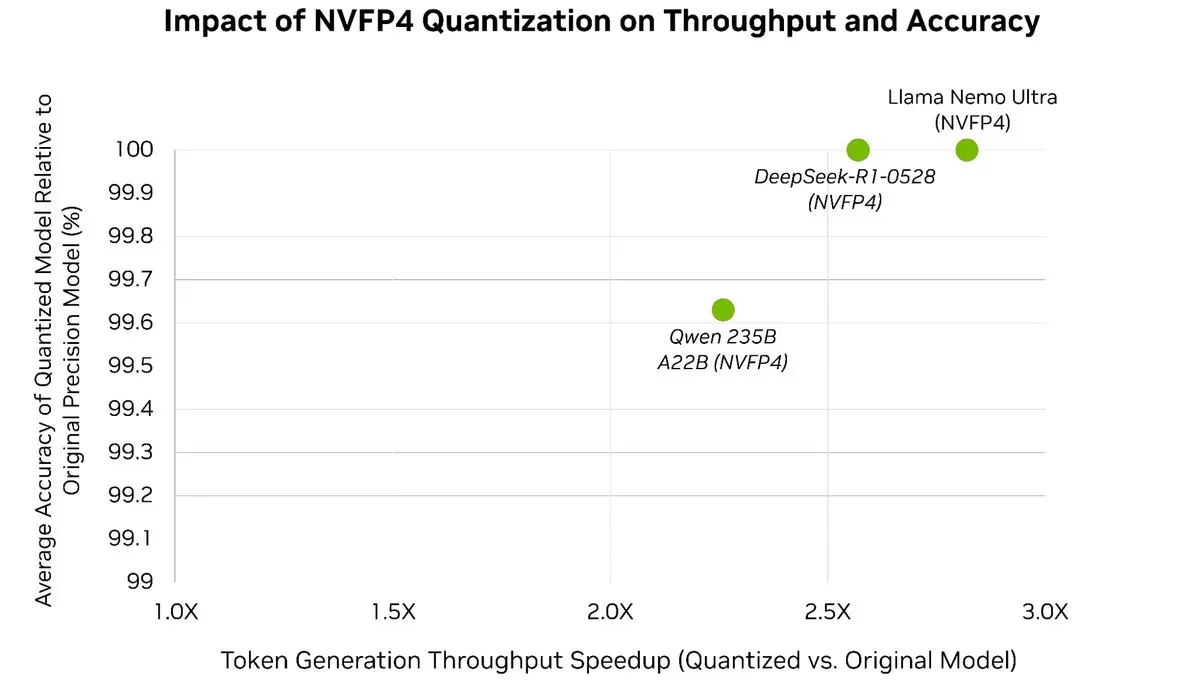
Accélérez facilement vos LLM jusqu'à 3x⚡️ tout en préservant plus de 99,5 % de la précision du modèle 🎯
Avec la quantification post-formation de TensorRT Model Optimizer, vous pouvez quantifier des modèles de pointe en NVFP4—réduisant considérablement la mémoire et la surcharge de calcul pendant l'inférence, tout en
Avec la quantification post-formation de TensorRT Model Optimizer, vous pouvez quantifier des modèles de pointe en NVFP4—réduisant considérablement la mémoire et la surcharge de calcul pendant l'inférence, tout en
Voir l'original
- Récompense
- 7
- 8
- Partager
Lionish_Lion:
SUIVEZ-MOI pour éviter les erreurs courantes de trading. Apprenez ce qui fonctionne vraiment grâce à mon expérience. ⚠️➡️👍 Évitez les pertes & apprenez à trader facilementAfficher plus
Nous avons expédié sa première version majeure, sur Pypi et GitHub.
Avec l'équipe, nous fabriquons des rob...
Avec l'équipe, nous fabriquons des rob...
MAJOR-4.59%
- Récompense
- 7
- 3
- Partager
AltcoinAnalyst:
D'après l'analyse de la chaîne de données, l'architecture stratégique doit encore être renforcée.Afficher plus
- Récompense
- 13
- 6
- Partager
AirdropSweaterFan:
On a râpé, ça y est, c'est fait~Afficher plus
Nous avons une fonctionnalité de base appelée le constructeur de prompts, qui est basée sur la méthode POST. Chaque étape comporte un Prompt, un Output, un outil et le S est pour la planification de l'ensemble du flux de travail. Nous allons bientôt publier de nombreuses mises à jour pour le constructeur afin de contrôler le flux des agents.
Voir l'original- Récompense
- 5
- 3
- Partager
HashRateHermit:
La mise à jour est de retour, je file, je file.Afficher plus
l'avantage cognitif est sensible aux attaques de clé de serrage
Voir l'original- Récompense
- 5
- 3
- Partager
ColdWalletGuardian:
Les tests de fiabilité sont très importants.Afficher plus
Nous avons expédié sa première grande version, sur Pypi et GitHub.
Avec l'équipe, nous créons rob...
Avec l'équipe, nous créons rob...
MAJOR-4.59%
- Récompense
- 12
- 2
- Partager
LiquidationWatcher:
Le progrès du développement est bon.Afficher plus
- Récompense
- 14
- 3
- Partager
SellTheBounce:
Encore un projet dont la technologie ne sent pas l'avenir.Afficher plus
- Récompense
- 14
- 5
- Partager
StakeWhisperer:
Enfin une solution fiable!Afficher plus
Que se passe-t-il maintenant après la dernière mise à jour :
Les bots deviennent plus intelligents.
Ils laissent un commentaire, puis nous bloquent.
Avant, c'était aléatoire.
Maintenant, ils analysent d'abord le post en utilisant l'IA et répondent que l'algorithme ne peut pas le signaler comme spam.
Donc ce n'est plus aléatoire 🥲
Pire..
Ils aiment leur
Les bots deviennent plus intelligents.
Ils laissent un commentaire, puis nous bloquent.
Avant, c'était aléatoire.
Maintenant, ils analysent d'abord le post en utilisant l'IA et répondent que l'algorithme ne peut pas le signaler comme spam.
Donc ce n'est plus aléatoire 🥲
Pire..
Ils aiment leur
NOT-5.35%
- Récompense
- 13
- 4
- Partager
retroactive_airdrop:
Bots enfin se sont mis à l'ouvrage...Afficher plus